Skip to content
#toc background: #f9f9f9;border: 1px solid #aaa;display: table;margin-bottom: 1em;padding: 1em;width: 350px; .toctitle font-weight: 700;text-align: center;
If a rule constraint obeys this property, it is antimonotonic. Rule constraints specify expected set/subset relationships of the variables within the mined rules, constant initiation of variables, and constraints on combination features and other forms of constraints.
Early methods of figuring out patterns in information embrace Bayes’ theorem (1700s) and regression evaluation (1800s). The proliferation, ubiquity and rising energy of pc expertise have dramatically elevated knowledge collection, storage, and manipulation capacity.
As knowledge mining can solely uncover patterns truly current in the data, the goal data set should be giant enough to comprise these patterns while remaining concise enough to be mined inside an appropriate time limit. Pre-processing is essential to research the multivariate knowledge units before knowledge mining. Data cleaning removes the observations containing noise and those with missing knowledge.
FS.internet includes coaching via stay on-line, and in individual sessions. FS.net is knowledge mining software program, and contains features similar to information extraction, data visualization, linked knowledge administration, and statistical analysis. Alternative competitor software program options to FS.web embody Coheris Analytics SPAD, Grooper, and NaturalText. limestats is a software enterprise fashioned in 2017 within the United States that publishes a software suite referred to as limestats. limestats is data mining software, and includes features corresponding to information extraction, data visualization, and statistical analysis.
Results generated by the info mining mannequin ought to be evaluated against the enterprise goals. Data mining is looking for hidden, valid, and probably useful patterns in huge information units.
Gregory Piatetsky-Shapiro coined the term “data discovery in databases” for the first workshop on the same subject (KDD-1989) and this time period became extra in style in AI and machine studying group. However, the time period knowledge mining grew to become extra in style within the business and press communities.
This will assist you to pick up some extra money for your business. Data Mining can also be explained as a logical strategy of discovering useful information to search out out useful information. Once you discover the knowledge and patterns, Data Mining is used for making choices for developing the enterprise. To answer the query “what is Data Miningâ€, we might say Data Mining could also be defined as the method of extracting useful info and patterns from enormous data. It consists of collection, extraction, evaluation, and statistics of information.
ELKI, GATE, KNIME, MEPX… No matter which information mining software you employ, you know it’s a course of that takes a considerable period of time. Just imagine that you just’re about to complete the process when your connection suddenly breaks and also you lose all the progress you’ve made, wasting your work and time. This can happen should you use your own server, whose connection can be unreliable. Limeproxies devoted proxy solutions have been influential in aiding companies collecting competitive intelligence via information mining course of. With the utilization of our proxies, the mining could be done with virgin IP which is cleanest and never used before.
Elegant, very exact models may be created in the tutorial setting when correct and dependable knowledge are readily available and the outcomes are identified. All of those limit the availability of and timely access to information, not to mention its reliability and validity. Ultimately, these elements can limit the analytical tempo, course of, and interpretation, as well as the general value of the outcomes. Data mining is a crucial a part of information discovery process that we can analyze an unlimited set of information and get hidden and useful knowledge.
It is common for knowledge mining algorithms to search out patterns in the coaching set which are not current within the basic data set. To overcome this, the evaluation LinkedIn Profile Scraper makes use of a test set of data on which the data mining algorithm was not skilled.
Data mining is the analysis step of the “data discovery in databases” course of, or KDD. Data mining is the core course of where a variety of complex and clever methods are utilized to extract patterns from data. Data mining process contains numerous tasks such as affiliation, classification, prediction, clustering, time series evaluation and so on. It may be outlined as the method of analyzing hidden patterns of data into significant info, which is collected and stored in database warehouses, for efficient analysis.
Once trained, the learned patterns could be utilized to the take a look at set of e-mails on which it had not been trained. The accuracy of the patterns can then be measured from what number of e-mails they accurately classify. Several statistical methods could also be used to evaluate the algorithm, corresponding to ROC curves. Before data mining algorithms can be used, a target information set have to be assembled.
Proprietary Data-mining Software And Applications
Data mining is the process of discovering patterns in giant information sets involving strategies on the intersection of machine learning, statistics, and database systems. It is an important course of the place intelligent strategies are utilized to extract data patterns. The final step of knowledge discovery from data is to confirm that the patterns produced by the data mining algorithms occur within the wider data set. Not all patterns discovered by data mining algorithms are necessarily valid.
Data mining software appears for patterns that typically happen and then looks for deviations. What causes somebody or one thing to deviate from the pattern? If yow will discover out why individuals deviate, you’ll find a approach to serve them.
Configure Proxy Settings On Centos 8/7 | Rhel eight/7 & Fedora 32/31/30
Data mining is the method of making use of these methods with the intention of uncovering hidden patterns in giant data units. Data mining is a process of discovering patterns in giant knowledge units involving strategies at the intersection of machine learning, statistics, and database systems.
Let’s research an example where rule constraints are used to mine hybrid-dimensional association rules. The complete process of knowledge mining can’t be accomplished in a single step. In other phrases, you can’t get the required information from the big volumes of information so simple as that.
What Are Proxy Servers?
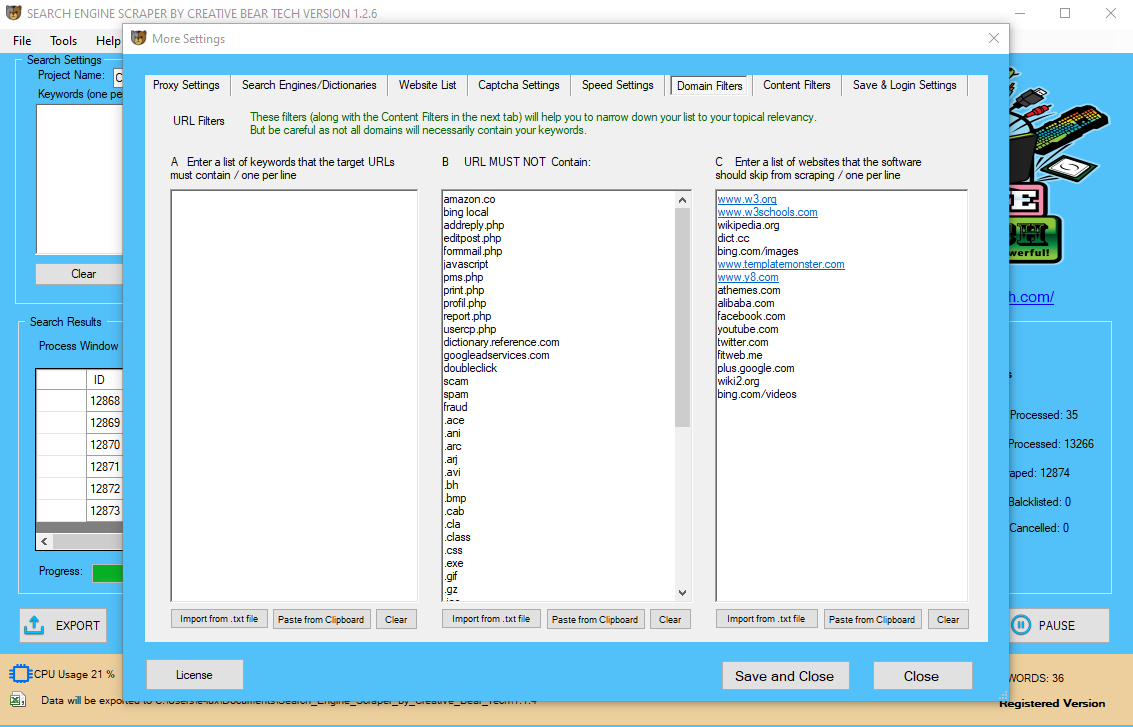
It’s a computing course of that allows a person to extract the knowledge and rework it into a clear google search scraper construction for future use. The handbook extraction of patterns from data has occurred for centuries.
- Now that we defined why it is crucial to use Residential IPs to carry your mining operations, we can focus on the actual operations intimately.
- The proliferation, ubiquity and growing energy of computer technology have dramatically increased information assortment, storage, and manipulation capacity.
- It’s a computing course of that allows a user to extract the data and transform it into a transparent construction for future use.
- Early strategies of figuring out patterns in information include Bayes’ theorem (1700s) and regression evaluation (1800s).
- As we talked about earlier, information mining means discovering giant sets of knowledge and analyzing them in order to uncover patterns in them.
- The guide extraction of patterns from data has occurred for centuries.
This is usually a recognition of some aberration in your information occurring at common intervals, or an ebb and circulate of a sure variable over time. For instance, you may see that your gross sales of a certain product seem to spike simply earlier than the holidays, or notice that hotter climate drives extra folks to your website. to the applied setting of public security and security has been creating models with operational worth and relevance.
The algorithms of Data Mining, facilitating business decision making and other info requirements to in the end cut back costs and enhance revenue. Web scraping has become a vital device for many companies when it comes to checking the competition, analyzing info or monitoring on-line conversations on specific subjects.
Data mining is utilized effectively not only within the business setting but additionally in other fields similar to climate forecast, drugs, transportation, healthcare, insurance, government…etc. Data mining has plenty of advantages when using in a selected trade. We will examine these advantages and downsides of data mining in several industries in a higher detail. The main concept in Data Mining is to dig deep into analyzing the patterns and relationships of information that can be used further in Artificial Intelligence, Predictive Analysis, etc. But the principle idea in Big Data is the supply, variety, quantity of knowledge and how to retailer and course of this amount of knowledge.
The discovered patterns are utilized to this check set, and the ensuing output is compared to the specified output. For example, an information mining algorithm attempting to differentiate “spam” from “reliable” emails can be skilled on a training set of sample e-mails.
Since they’ve IPs with real addresses, websites rarely flag determine them as proxies. They are, therefore, safer and reliable since they’re much less prone to be blocked by websites.
Currently, the phrases data mining and knowledge discovery are used interchangeably. Smartproxy proxies are residential IP addresses, which have a really excessive success price and are excellent for scraping and data mining.
Myprivateproxy
Now that we explained why it’s crucial to use Residential IPs to hold your mining operations, we are able to focus on the precise operations in detail. As we mentioned earlier, information mining means discovering giant units of information and analyzing them to be able to discover patterns in them.
Using Residential IPs will lower your fail rate; and if you get higher results out of your knowledge mining actions, you can say that by paying for a great proxy you get a much bigger return on investment (ROI). If the realized patterns don’t meet the specified standards, subsequently it is essential to re-consider and alter the pre-processing and data mining steps. If the discovered patterns do meet the specified requirements, then the ultimate step is to interpret the learned patterns and switch them into knowledge. These strategies can, however, be used in creating new hypotheses to test in opposition to the bigger information populations. Consider a advertising head of telecom service supplies who wants to extend revenues of long distance providers.
Alternative competitor software choices to limestats include DataMelt, Indigo DRS Data Reporting Systems, and FS.internet. Diffbot offers a collection of merchandise to show unstructured knowledge from throughout the net into structured, contextual databases.
Users sometimes make use of their knowledge of the appliance or data to specify rule constraints for the mining task. These rule constraints may be used together with, or as an alternative to, metarule-guided mining. In this part, we study rule constraints as to how they can be utilized to make the mining course of extra efficient.
Because of those options, residential proxies are significantly suited for information mining for business analysis. Data mining is the process of looking at giant banks of information to generate new info. includes gaining an understanding of the present practices and general goals of the project. During the business understanding section of the CRISP-DM process, the analyst determines the goals of the data mining project. Included on this section are an identification of the resources obtainable and any related constraints, overall objectives, and particular metrics that can be used to evaluate the success or failure of the project.
This usually includes utilizing database techniques such as spatial indices. These patterns can then be seen as a sort of summary of the enter information, and may be utilized in additional evaluation or, for example, in machine studying and predictive analytics. For example, the information mining step might identify a number of groups in the information, which might then be used to obtain extra accurate prediction results by a decision support system. Neither the data assortment, knowledge preparation, nor end result interpretation and reporting is part of the info mining step, but do belong to the general KDD course of as further steps. One of probably the most primary methods in information mining is studying to acknowledge patterns in your information sets.
Constraints are knowledge-succinct if they can be utilized initially of a sample mining course of to prune the information subsets that can’t fulfill the constraints. Suppose we are using the Apriori framework, which explores itemsets of dimension k on the kth iteration. In other phrases, if an itemset doesn’t satisfy this rule constraint, none of its supersets can satisfy the constraint.
We will also undergo a few of the best scraping technologies and tools so you may make an knowledgeable decision on which providers will work best for you. Data mining requires information preparation which uncovers information or patterns which compromise confidentiality and privacy obligations. This isn’t knowledge mining per se, however a results of the preparation of knowledge earlier than—and for the purposes of—the analysis.
Coheris is a software program enterprise in France that publishes a software suite known as Coheris Analytics SPAD. Coheris Analytics SPAD contains coaching by way of in person periods. The Coheris Analytics SPAD product is SaaS, and Windows software program. Alternative competitor software options to Coheris Analytics SPAD include Grooper, Indigo DRS Data Reporting Systems, and NaturalText.
The time period knowledge mining appeared around 1990 within the database community, typically with optimistic connotations. Other terms used embrace data archaeology, data harvesting, data discovery, information extraction, etc.
Proxy Key personal proxy options have been instrumental to serving to firms collect competitive intelligence by way of knowledge mining. Our proxies might help diversify your knowledge mining activities over a big community of anonymous and clean IP addresses. You will be able to entry a large quantity of knowledge in the most efficient and moral method.
The information or data found during data mining process must be made simple to know for non-technical stakeholders. In this section, patterns recognized are evaluated towards the business goals.
It is a really complicated process than we predict involving a number of processes. The processes together with data cleansing, knowledge integration, data selection, data transformation, data mining, pattern analysis and information illustration are to be accomplished in the given order. Visualization is used initially of the Data Mining process. It is useful for converting poor knowledge into good information letting completely different kinds of methods to be used in discovering hidden patterns.
Data Mining is all about discovering unsuspected/ beforehand unknown relationships amongst the information. Symbrium is a software business fashioned in 1978 in the United States that publishes a software program suite referred to as FS.web.
Collect Any Web Data,from Any Website.
For high ROI on his sales and advertising efforts customer profiling is essential. He has a vast information pool of buyer info like age, gender, earnings, credit score historical past, etc. But its inconceivable to find out traits of people who choose lengthy distance calls with guide evaluation. Using knowledge mining strategies, he may uncover patterns between high lengthy distance name customers and their traits. In the deployment phase, you ship your data mining discoveries to on a regular basis business operations.
Clustering Analysis
Data mining is used for analyzing uncooked data, together with sales numbers, costs, and customers, to develop higher advertising strategies, enhance the efficiency or lower the prices of working the enterprise. Also, Data mining serves to discover new patterns of habits amongst consumers.